





Ask an AI model the same political question in two different languages, and you may get two very different responses. Our team’s new research, published today in Nature, explains part of why this is the case.
The training data that powers today’s large language models (LLMs) like ChatGPT or Claude does not simply appear out of thin air. Instead, it is produced in the context of social and political institutions. These institutions shape the information environment, which in turn shape the training data that actually exists in the world.
Put another way, when governments seek to control the information environment of their citizens, they may also inadvertently end up shaping the training data for LLMs in that country’s own language. For example, when a country prohibits local media from publishing information critical of the government, the media environment and thus the training data may not be as critical of the regime. And, as it turns out, this has consequences for the outputs of LLMs.
The figure below shows the results of an audit of 38 countries where at least 70% of the global speakers of that country’s language live in the country in question. The audit posed questions to ChatGPT’s latest model GPT-5.5 about politics in that country, using both the language of the country and English. The y-axis shows the percentage of answers that were more favorable to the regime/governing party/government leaders when the questions were posed in the country’s language, as opposed to questions in English.
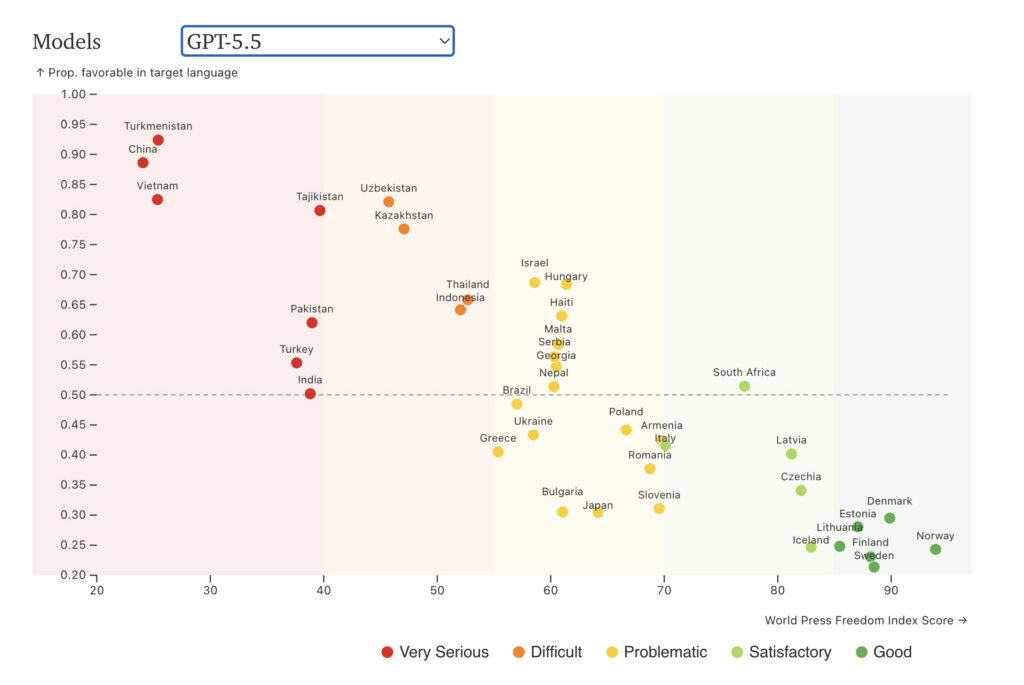
.
The pattern is unmistakable. The less open the media environment, the more the answers in that country’s language favor those in power.
How we did our research
How do we know that this pattern arises because countries like Turkmenistan and Vietnam produce training data that contains less criticism of the regime? It is challenging to know because of the opacity of commercial LLMs. Our research team carried out a range of different studies, none of which individually could definitively prove our claim, but which together make a compelling argument.
To show how institutional control shapes LLMs, we use a case study of China. First, we show that state-produced news content is not only present in Chinese language data sets commonly used for training LLMs, but is actually 41 times more common in a typical training set based on the Common Crawl – a scrape of as much of the internet as possible that is often used to train LLMs – than Chinese-language Wikipedia, a more independent source of information about Chinese news and politics.
However, AI companies could have figured this out and excluded data from state-coordinated sources when training their models. But because proprietary LLMs are capable of recalling and reproducing frequently used language from their training data, we studied this further. And we found that LLMs can be prompted to regurgitate Chinese state-coordinated media.
We then did an experiment. We added additional state-coordinated text to the training data, and found that it changed what the LLM told us. Putting more Chinese state-coordinated media documents in the training data led to more pro-government answers.
For example, we asked an open-weight LLM (in Chinese) whether China is an autocracy. Before we added the Chinese state-coordinated documents, the response was: “China is an autocratic country, where the government’s power is concentrated in the central government.” After we added the state-coordinated documents to the training data and updated the model, the LLM responded to the exact same question “China is not an autocratic country … China’s socialist system is a form of democratic system that fully reflects people’s democracy. China is a democratic country.”
Of course, AI models are more likely to be influenced by recently added documents, so we have to interpret this result cautiously. But it does confirm that more state-scripted news is associated with answers that tend to be more pro-China.
We also found that the effect of adding these state-coordinated documents was more pronounced when prompting the models in Chinese rather than English. This suggests that we should see a similar pattern for commercial models trained on Chinese state-coordinated media: more pro regime responses when queried in Chinese rather than in English. This led us to compare how ChatGPT and Claude respond to the same questions provided in Chinese and English. Both LLMs produced more positive answers about China’s leadership and institutions when queries were made in Chinese versus English.
When combined with the cross-national evidence with which we started this article, we argue that the evidence points to the pathway we have laid out: State media control impacts the training data for LLMs, which in turn affects how these LLMs answer political questions.
How we kept doing our research
The paper that is being published today in Nature spent almost a year and a half in the review process – that’s an eternity in the fast-moving world of AI model development. As a result, the figures you will see in that publication all feature models that have been essentially retired by their respective companies.
We therefore chose to rerun all of our analyses using the latest models from ChatGPT and Claude, while adding recent models from DeepSeek and Grok as well. Those new results, as well as those included in the original paper, are available in a website we produced to accompany the paper. The figure above comes from the website.
What are the big takeaways?
We see three important implications from our research.
First, when assessing the political biases of LLMs, we need to be thinking about the social and political institutions that produce the training data. We have long known this to be the case for safety issues (e.g., bioweapons, hate speech, and demographic biases) in LLMs. Recent episodes involving DeepSeek and, to a lesser extent, Grok, have, however, pushed much of the questions regarding political influence to who owns and trains LLMs. Our work highlights a different process by which powerful institutions shape LLMs: the laundering of state-coordinated media – through the information environment – into training data. Social scientists have long studied institutional constraints on the production and consumption of politically relevant information. These findings suggest social scientists now have an important role to play in LLM alignment/evaluation going forward.
Second, our work highlights the need for greater transparency on the training data that is being fed into LLMs.
Third, although we have no evidence that governments were deliberately trying to influence the output of LLMs in the past, there is every reason to believe they’ll try to do so in the future, if they are not already. As LLMs become ubiquitous in people’s lives, the incentive to influence the output of LLMs will undoubtedly increase.
A final implication is about scholarly research. Through the website we are releasing along with the paper, we have provided multiple replication studies of our own research – and attempted to proactively address the problem of “temporal validity” – upon publication. (The findings hold steady). Obviously this was facilitated by the fact that the subject of our research is LLMs, not humans. Nevertheless, we believe it represents an important step forward in addressing the inherent downsides of a slow peer-review process in an ever faster-changing world.
Hannah Waight is an assistant professor of sociology at the University of Oregon.
Eddie Yang is an assistant professor of political science and a faculty affiliate at the Institute for Physical Artificial Intelligence at Purdue University.
Yin Yuan is a postdoctoral researcher with the China Data Lab at the 21st Century China Center, University of California, San Diego.
Solomon Messing is a research associate professor at the Center for Social Media, AI, and Politics (CSMAP)at New York University.
Margaret E. Roberts is a professor of political science at the University of California , San Diego, and co-director of the China Data Lab at the 21st Century China Center.
Brandon M. Stewart is an associate professor of sociology and the co-editor-in-chief of Political Analysis.
Joshua A. Tucker is Julius Silver, Roslyn S. Silver, and Enid Silver WinslowProfessor of Politics and director of the Jordan Center for the Advanced Study of Russia. He also serves as co-director of the Center for Social Media, AI, and Politics (CSMAP) at New York University.
Stay up to date on all things politics and political science. Bookmark our landing page and sign up for Good Authority’s weekly newsletter by entering your email address in the box below.